How We Beat Claude Opus with a Smaller Model.
Stop burning tokens on brute force. If you’re using coding agents but seeing diminished ROI, this breakdown is for you.
And cut our per-task token bill in the process.
TL;DR: Orchestration beats brute reasoning, a better harness yields higher accuracy for less money.
The AI Token Trap
For the last two years, the standard way to improve a coding agent has been simple:
Pay more for a bigger model.
Buying more "reasoning" is a brute-force solution. We chose a different path.
We didn't buy a bigger model. We built an architecture-first model harness optimized for production-grade systems
Can a better harness beat a frontier model on the industry's most brutal benchmark?
The Arena: Terminal-Bench 2.0
Terminal-Bench is the industry-standard evaluation framework for AI agents.
- The Tasks: 89 real-world scenarios.
- The Test: Diverse, multi-step problems.
- The Result: Programmatic verification. You either solve it, or you don't.
Wait, What is a Harness?
The AI Model: Just ingests and outputs text.
The Harness: The environment around theAI. It handles memory, multi-step workflows, tool execution, and verification loops.
The Model is the engine; the Harness is the entire car.
predev and Claude Code are harnesses; Sonnet and Opus are models.
The Competitors
predev + Sonnet 4.6 vs Claude Code + Opus 4.5
We ran predev + Sonnet 4.6 on the harbor reference harness against the Terminal-Bench 2.0 task set.
Configuration: n=89, pass@1, identical task IDs.
The Claude Code numbers were taken directly from their public submissions on tbench.
The Verdict
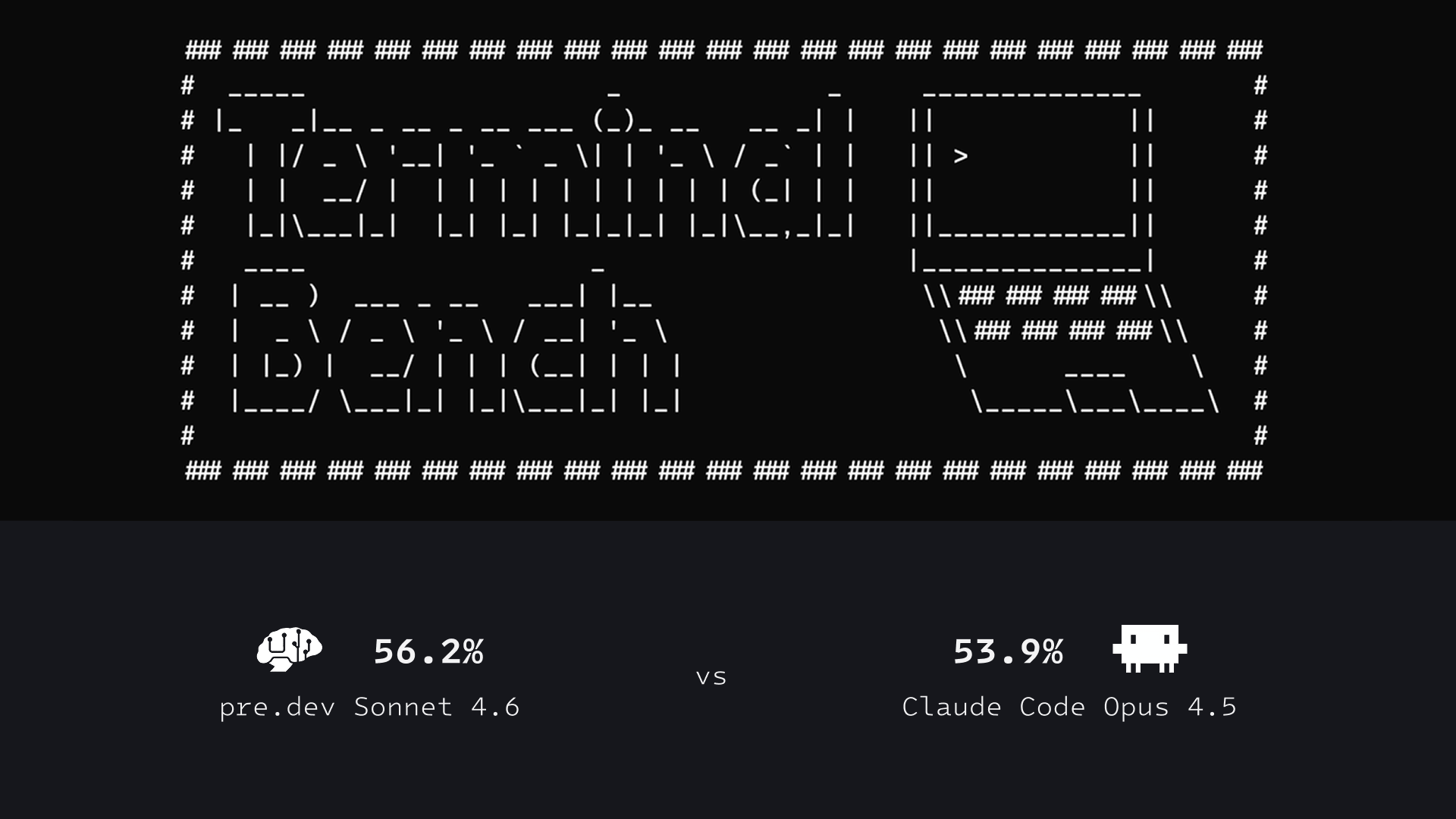
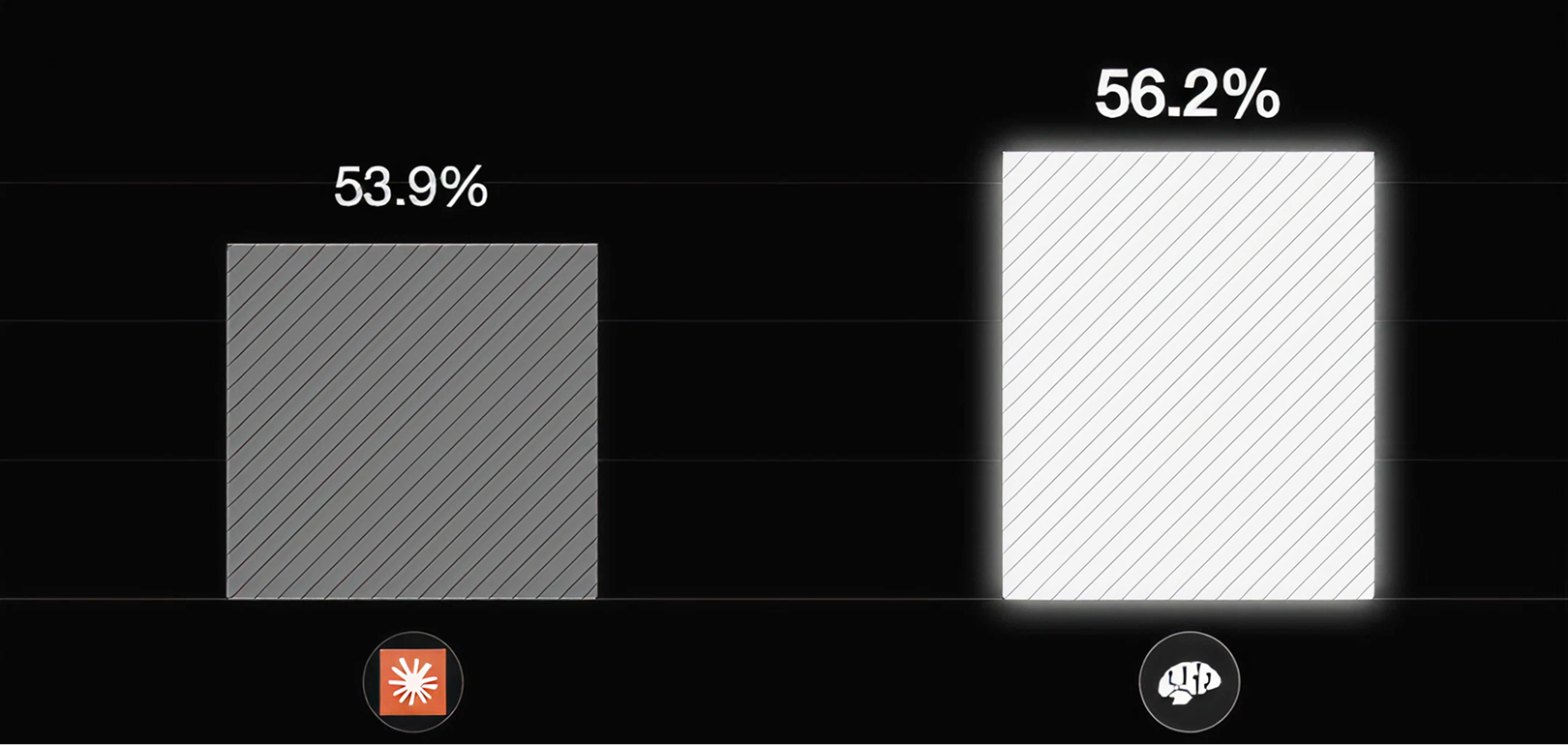
- predev + Sonnet: 56.2%
- Claude Code + Opus: 53.9%
We dropped an entire model tier and still finished ahead.
Efficiency > Brute Reasoning
The agent's architecture matters more than its weights.
Accuracy went up, while the per-task model bill went down.
How We Did It
The Core Architecture:
- Plan Before Code: Extracts a structured blueprint before touching a file.
- Dynamic Execution: Uses ToDo dependency graphs to solve non-linear problems.
- Strict Verification: A blind verifier re-runs acceptance criteria and freely disagrees.
Who is This For?
We built predev for real-life scenarios where ROI matters.
Our customers include:
- Agencies building for their clients.
- Vendors building PoCs for their prospects.
- Enterprise teams building internal data pipelines.
- Star tups getting their MVP out on time and on budget.
The Takeaway
If ROI matters to your business, stop burning tokens on brute force.
You don't need a frontier lab to beat one.
You just need a system engineered for the actual work.
If this applies to you, please reach out to discuss optimizing your token spend.
The Data:
If you want to explore the whole benchmark in detail, head over to Adam's full break-down.
The Open-Source Trajectories & Harbor Results are available on GitHub.