Self-Driving Agentic Engineering: The End of Coding Agent Amnesia


In February 2026, Andrej Karpathy quietly retired the term he'd made famous. A year after coining "vibe coding" in a throwaway tweet that got 4.5 million views, he reframed the future as something different: agentic engineering. The distinction matters. "There is an art & science and expertise to it," he wrote. "The goal is to claim the leverage from the use of agents but without any compromise on the quality of the software."
That last phrase is doing a lot of work. Without any compromise on quality. Because if you've spent the past year trying to build anything real with AI coding tools, you know exactly what compromise he's talking about.
pre.dev operates like a software team in your browser: a PM plans, an architect blueprints system, coding agents build, and then deployment is seamless and scalable.
The Leverage Is Real. The Compromise Is Killing It.
Let's be honest about where things stand. The 2025 Stack Overflow Developer Survey — 49,000+ developers, 177 countries — tells a story of mass adoption paired with mass frustration. 84% of developers now use AI tools. Only 33% trust the output. The top complaint, cited by 66% of respondents: AI solutions that are "almost right, but not quite." Nearly half said debugging AI-generated code takes longer than writing it themselves.
Addy Osmani, who leads Chrome's developer experience at Google, gave this a name: The 70% Problem. You get 70% of the way there fast — shockingly fast — but that final 30% becomes an exercise in diminishing returns. The hard parts of software development — understanding requirements, designing maintainable systems, handling edge cases — still require judgment that doesn't emerge from a prompt.
David Cramer, CTO of Sentry, spent two months building a production service exclusively with AI agents and concluded that refining their output constitutes 95% of the actual work. Manually checking for duplicates, improving maintainability, catching instructions the agent just ignored. Even when the code appears to work, it's unmaintainable.
CodeRabbit's analysis of 470 GitHub PRs quantified the damage: AI-generated code produces 1.7x more issues than human code, 3x more readability problems, and 8x more performance inefficiencies.
This is the compromise Karpathy is talking about. And the entire industry — Cursor at $29.3B, Devin at $10.2B, Lovable at $6.6B — is racing to solve it by making models better at one-shotting things.
The research says that's the wrong approach entirely.
Two Hard Ceilings Nobody Wants to Talk About
Every AI coding agent hits two structural walls, and no amount of model improvement eliminates either one.
The context ceiling. The "Lost in the Middle" paper from Stanford and UC Berkeley showed that LLM performance drops over 20% when relevant information sits in the middle of a long context window. Chroma's Context Rot research tested 18 frontier models — GPT-5.2, Claude Opus 4.6, Gemini 3, all of them — and found that every single one degrades as input length grows, even when they ace simple needle-in-a-haystack benchmarks. Real agentic tasks involve far more ambiguity than those benchmarks capture.
Anthropic's engineering team formalized this as a finite resource problem: every new token depletes the model's attention budget. Good context engineering means finding the smallest possible set of high-signal tokens that maximize the likelihood of the desired outcome. You can't just dump your codebase into a prompt and expect coherence.
The duration ceiling. METR's landmark study measured that frontier models have a "50% time horizon" of about 50 minutes — near-perfect success on tasks a human finishes in under 4 minutes, but less than 10% success on tasks requiring more than 4 hours. Scale AI's SWE-Bench Pro confirmed this on real codebases: the best models in the world score roughly 23% on enterprise-level, multi-file tasks. Performance degrades sharply as solutions require more files and more lines.
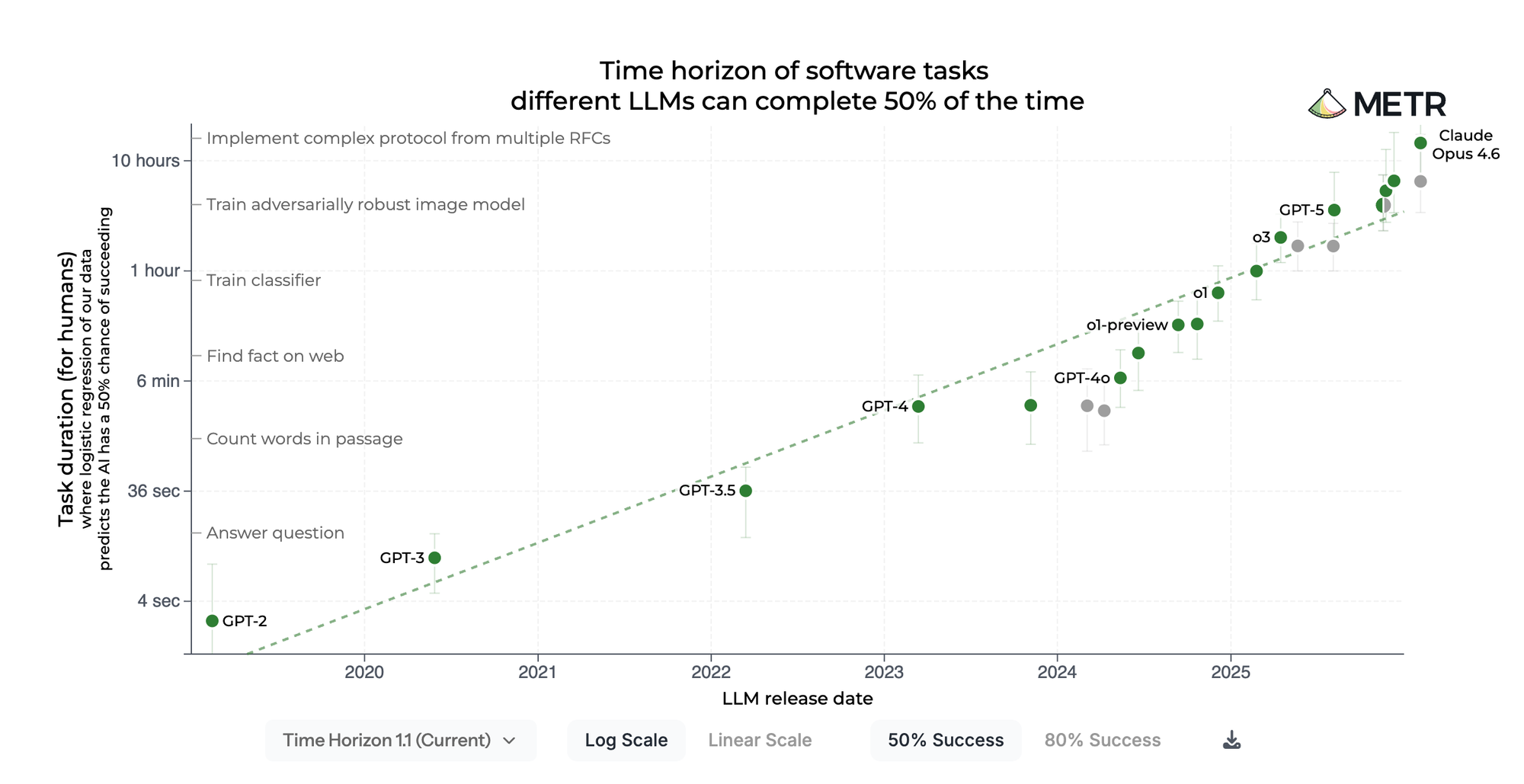
Anthropic's own team documented the dominant failure mode: agents try to do too much at once — essentially attempting to one-shot an entire application — run out of context mid-implementation, and produce something that looks complete but isn't tested or working. Their conclusion was blunt: "Even a frontier coding model running in a loop across multiple context windows will fall short of building a production-quality web app if it's only given a high-level prompt."
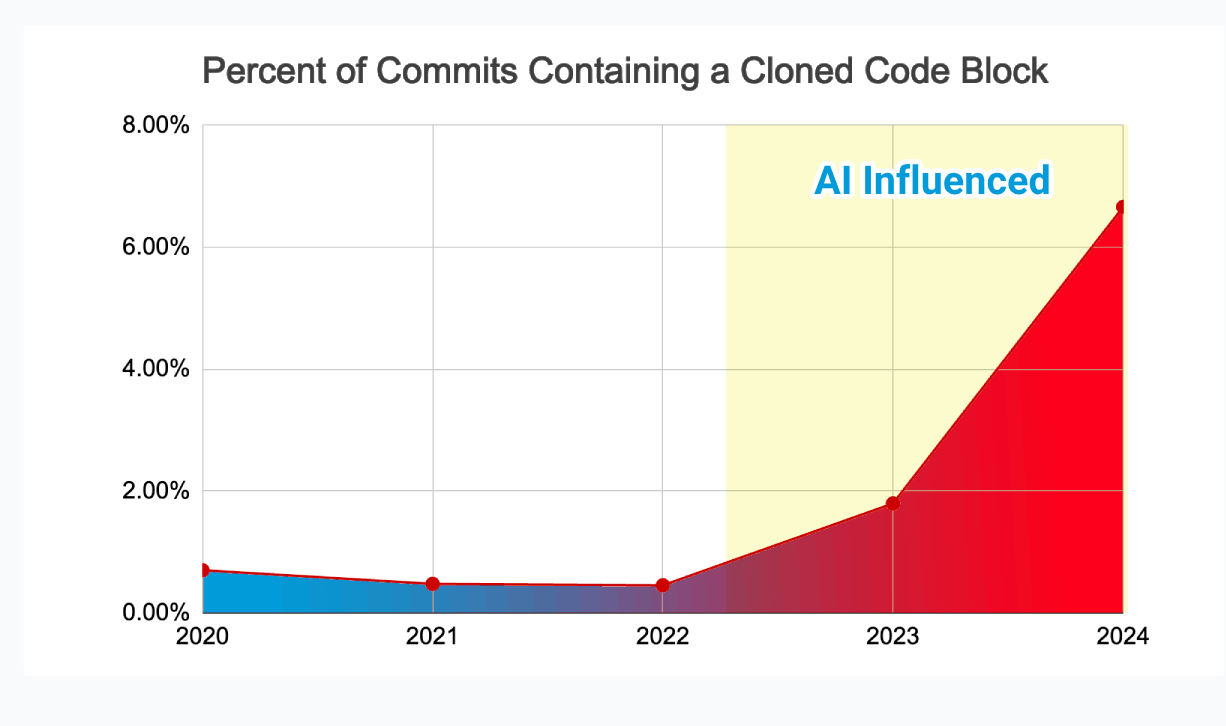
So the models are powerful in bursts but can't maintain coherence across complex systems. And the GitClear analysis of 211 million changed lines showed what happens when you ship burst-generated code anyway: code churn has nearly doubled since AI adoption took off, while refactoring activity collapsed. We're writing more code faster and spending more time fixing it. That's not productivity — it's a treadmill.
Planning Is the Multiplier
Here's where the research gets genuinely interesting, and where the concept of agentic engineering starts to take shape.
PlanSearch, from Scale AI, demonstrated that searching over candidate plans in natural language before generating code boosted Claude 3.5 Sonnet's pass rate from 60.6% to 77.0% — a 27% relative improvement from the exact same model, just by planning before coding. The Self-Planning Code Generation paper in ACM TOSEM showed up to 25.4% improvement in correctness when LLMs decompose problems into steps before writing a single line.
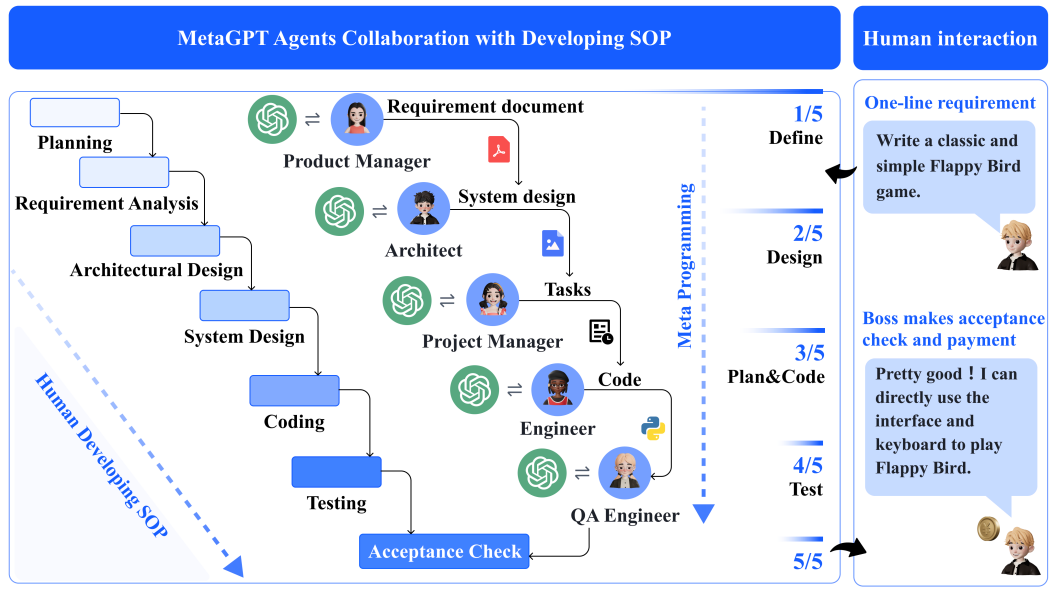
The multi-agent research is even more compelling. MetaGPT, an ICLR 2024 Oral paper, introduced an assembly-line architecture with specialized agents — Product Manager, Architect, Project Manager, Engineer — each producing structured artifacts like PRDs and system designs. It achieved 100% task completion on its benchmark because the structured handoffs prevented what the authors called "cascading hallucinations" from naively chaining LLM calls.
Anthropic found that their multi-agent research system — an orchestrator delegating to specialized subagents with dedicated context windows — outperformed a single agent by 90.2% on complex tasks.
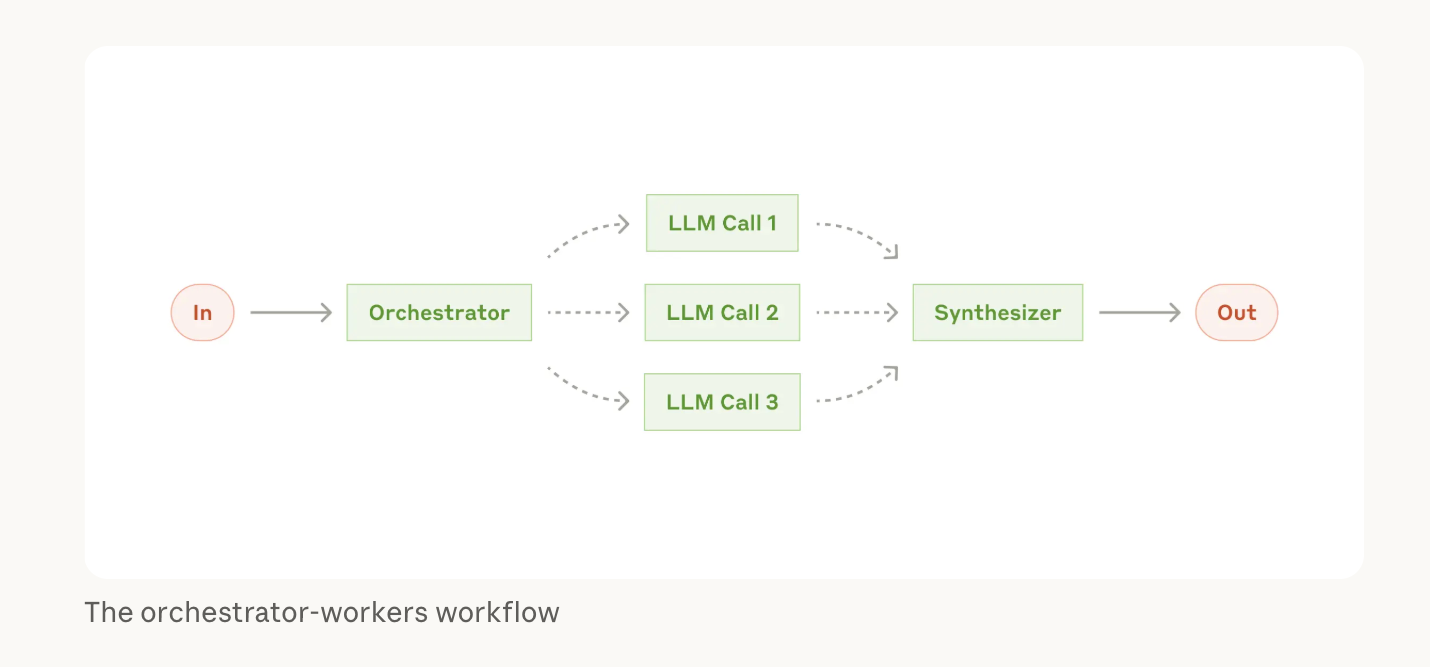
The pattern across all of this work is the same: the specification is the leverage. Not better prompts. Not bigger context windows. Not faster inference. Structured decomposition of what needs to be built, before any code gets written.
This is what Karpathy means by agentic engineering. It's not vibe coding with guardrails. It's the recognition that the planning is the product — the code is just the output.
What This Looks Like in Practice
This is the thesis behind Pre.dev, and I want to be direct about why it matters.
Every other tool in this space starts with code generation. You open a prompt, describe what you want, and the AI starts writing immediately. That's the vibe coding paradigm, and we've just walked through why it hits a wall at scale.
Pre.dev operates like a real software team. When you describe what you want to build, a Product Manager agent plans your roadmap and requirements. An Architect agent designs the system blueprint — database schemas, API contracts, service boundaries, authentication flows. Only after that planning layer produces a complete specification do advanced coding agents get deployed to research, build, and verify the actual code. Then the whole thing deploys to scalable infrastructure in one sitting.
This directly addresses every failure mode in the literature:
Context management — instead of cramming an entire application into one context window (where we know models degrade), the planning layer decomposes the system into well-scoped units. Each coding agent receives exactly the context it needs — the relevant spec, the schema it's implementing against, the API contract it must satisfy — and nothing more. This is the "smallest set of high-signal tokens" approach that Anthropic's context engineering research prescribes.
Long-running coherence — the specification serves as a persistent source of truth across agent invocations. Agents can work in parallel on different parts of the system and still produce code that integrates correctly, because they're all building against the same blueprint. No drift. No hallucination compounding across tasks.
Alignment without babysitting — Cramer's 95%-is-refinement problem comes from agents with no specification to be accountable to. When there's a detailed plan, verification becomes tractable. You check whether the agent built what the spec says, not whether it vibed its way to something roughly right.
Economics — Stevens Institute research found that retry-based agent loops consume up to 50x the tokens of a single pass. Planning first means you're not burning tokens on the model arguing with itself. You're spending them on construction.
The whole thing runs in your browser. No local setup, no CLI, no DevOps knowledge required. Twenty free credits to start at pre.dev.
The Shift Is Already Happening
Jellyfish CEO Andrew Lau captured the transition precisely: when someone writes and refines a prompt, they're effectively writing a specification — defining behavior, constraints, and outcomes. That starts to resemble architecture management, or even product management.
Microsoft's CTO predicts 95% of code will be AI-generated by 2030. Gartner reported a 1,445% surge in multi-agent system inquiries in a single year. The industry is waking up to the fact that the bottleneck was never code generation. It was always planning.
Karpathy saw it. The research confirms it. The question isn't whether AI will write most of the code — it will. The question is whether that code will actually work. Whether it'll be maintainable, secure, aligned with requirements, and production-ready.
The answer has never been "write better prompts." It's always been "write better plans." Each step of the plan is a slice of the prompt and the agent is always oriented and aware of your requirements.
That's what self-driving agentic engineering means. Not vibes. Not hope. A system that plans like a team, builds like a team, and ships software you can actually trust.
Get started with 20 free credits at pre.dev →
Like and subscribe for more content on our YouTube and X:
YouTube: https://www.youtube.com/@predotdev, X: @predotdev,
Citations
- Karpathy, A. (Feb 2025). "Vibe coding" tweet. X.
- Karpathy, A. (Feb 2026). "Agentic engineering" follow-up. X.
- Stack Overflow. (Jul 2025). 2025 Developer Survey — AI Section. 49,000+ respondents, 177 countries.
- Osmani, A. (Dec 2024). The 70% Problem: Hard Truths About AI-Assisted Coding. Substack.
- Cramer, D. (Aug 2025). Built With Borrowed Hands. cra.mr.
- CodeRabbit. (Dec 2025). State of AI vs Human Code Generation Report. Yahoo Finance / CodeRabbit.
- Liu, N. et al. (2024). Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics (TACL).
- Hong, J., Troynikov, A. & Huber, J. (Jul 2025). Context Rot: How Increasing Input Tokens Impacts LLM Performance. Chroma Research.
- Anthropic. (Sep 2025). Effective Context Engineering for AI Agents. Anthropic Engineering Blog.
- Kwa, T. et al. (Mar 2025). Measuring AI Ability to Complete Long Tasks. METR.
- Deng, Y. et al. (Sep 2025). SWE-Bench Pro. Scale AI.
- Anthropic. (2025). Effective Harnesses for Long-Running Agents. Anthropic Engineering Blog.
- GitClear. (2025). AI Assistant Code Quality 2025 Research. 211M changed lines analyzed.
- Wang, E. et al. (Sep 2024). PlanSearch: Planning In Natural Language Improves LLM Search For Code Generation. arXiv.
- Jiang, X. et al. (2024). Self-Planning Code Generation with Large Language Models. ACM Transactions on Software Engineering and Methodology (TOSEM).
- Hong, S. et al. (2024). MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. ICLR 2024 (Oral).
- Anthropic. (Jun 2025). How We Built Our Multi-Agent Research System. Anthropic Engineering Blog.
- Stevens Institute of Technology. (2025). The Hidden Economics of AI Agents: Managing Token Costs and Latency.
- Lau, A. / McKinsey. (2025). Measuring AI in Software Development. McKinsey & Company.